

Technical SEO can become rather complex, especially if you are looking for errors in your site. When facing an SEO audit, or you aim to improve your CTR or impressions within Google, crawlability plays a huge role in rankings. Below I have addressed, as simply as possible, 10 crawlability issues affecting your website’s SEO, along with how to find them.
What are Crawlability Problems?
Before getting started understanding what a crawlability problem means for your website is extremely important. A crawlability problem can be anything that does not allow Search Engine Bots to crawl (or navigate) through the pages of your website. In a general sense, the most common reasons your website is not being crawled correctly would be due to:
- Nofollow links that limit link quality and ownership.
- Redirect loops create a nonstop cycle between multiple pages.
- Poor sitemap and website structure.
- Slow website speed discouraging bots to crawl.
Crawlability problems affect your SEO by making many of your website pages practically invisible to Search Engines. Without proper auditing and constant supervision, your website could face a snowball effect with multiple crawlability problems. Overall, this will downrank your website, which I have seen greatly affect huge, well-known websites go from number 1 on Google, to not even on the first page.
10 Crawlability Issues Affecting Your Website
#1 Pages Blocked in Robots.txt
Search engines will first look at your robots.txt file which you can access through your website’s settings. Here, you can determine which files should be crawled and which should be disallowed.
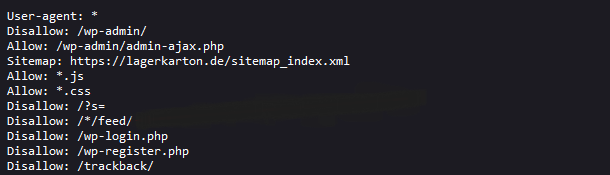
Typically, if you are using a WordPress SEO plugin like RankMath, they filter the robot.txt files for you. Otherwise, you will have to go into your website robot.txt file and type “Disallow: /” or “Allow: /” and type the url extension.
#2 No Follow Links
No follow links can be placed on pages accidentally or perhaps on purpose as it is information only for users who are directed manually to the page. Either way, a nofollow tag tells search engines to not crawl the links on the webpage. To find a tag similar to this, search for the following code to your webpages:
<meta name:“robots” content:“nofollow”>
The easiest way you can check for nofollow links is using the Site Audit Tool on Semrush or Ahrefs. Simply open the tool, type in the name of your website, and select “Start Audit”.
#3 Bad Website Structure
Website Architecture is the foundation of a good, readable website. If your site structure is disorganized or has orphaned pages, not only are those pages not properly indexed, but search engines will struggle to understand your website, making it practically unreadable.
Ensure you have a well structured site architecture in place that properly organizes all of your pages according to each category. If you need to locate orphaned pages, simply type “orphan” in SEMrush’s Site Audit tool.
#4 No Internal Links and Linking Strategy
Internal links play a crucial role not only for users, but also for web crawlers to properly navigate your website internally. Usually, you need at minimum 3 internal links per page. These internal links should also have a relevance to the keyword your content covers on the webpage.
As mentioned above, you can use a Site Audit tool to locate all orphaned pages to provide them with internal links associated to their category. This will help bring your website back to a better structured site, with easy to follow links.
#5 Sitemap XML Management
A Sitemap provides all crawlable URLs and pages that are available on your website. If you want search engines to crawl, index and rank your pages, good Sitemap management is required.
If your Sitemap does not include any pages you want to rank, they may go unnoticed. To combat this, the best way to fix this is to use a Sitemap tool such as XML Sitemap Generator which helps you to include all wanted pages to be indexed/crawled.
#6 ‘Noindex’ Tags
A ‘Noindex’ tag instructs search engines to simply not crawl that particular page or post. While this is supposed to help organize which posts you want indexed and which you don’t, this can still cause crawlability issues if it is applied to a page for a long period of time. Example of a noindex tag would be:
<meta name:“robots” content:“noindex”>
If you have a ‘noindex’ tag for a long period, Google will consider the tag as a ‘nofollow’, which can affect your website’s SEO and overall crawlability. Ensure all ‘noindex’ tags are intentional, and if possible, as a temporary solution.
#7 Slow Site Speed
As soon as a search engine bot begins to crawl your site, they are only given a specific amount of time to do so. This crawlability time is usually referred to as a crawl budget.
A slow site speed means fewer pages can be crawled, due to slow page uploading times. To fix this, ensure there is no extra HTML code that is not being used, images are compressed, and your site is optimized for mobile use. Search engine bots typically crawl through mobile versions of your website, so your website must be optimized for mobile accessibility.
#8 Internal Broken Links
Too many broken links (404 pages) can internally damage your website’s crawlability. This can lead to preventing search bots from accessing the linked pages. To find these broken links, use your Site Audit tool.
Instead of linking to unpublished URLs, or error pages, link to other published pages that can temporarily replace the error pages until fixed.
#9 URL Parameters
URL parameters (a.k.a query strings) are parts of a URL that keep track and organize pages followed by a question mark (?). These can become very confusing for search engines, and cause major crawlability issues, as these URL parameters can create an infinite amount of strings.
To remove URL parameters, ensure you go into your robots.txt and disallow “?s”.
#10 Redirect Loops
Redirect loops happen when one page redirects to another, which is already redirecting to the original page. This creates a continuous loop that can damage crawlability for your website.
To find these loops, look up your redirects and ensure each page is being redirected to a functioning, crawlable page.
Other Tips to Create a Crawlable Website
While the top 10 crawlability issues can be quickly addressed, some other great tips are to ensure no cannibalism or duplicate content is created within your website. This is actually a very common practice that we can sometimes look over as pillar content is distributed across all pages.
Either way, using audit tools and understanding some code can go a long way in addressing crawlability issues. For a better SEO, practicing these audits monthly can greatly increase your website’s performance, and become more readable for not only search engine bots but also for users.


